
Amazon Redshift Zero-ETL実験室 〜素朴な疑問を徹底的に検証する!
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。先日、Amazon Aurora PostgreSQLとAmazon DynamoDBのAmazon Redshiftへの Zero-ETL 統合が一般提供を開始しました。これらのZero-ETL環境の検証ブログやさまざまなアップデートについて紹介してきました。本日は、一般提供開始時点のZero-ETLの検証を通じて気になった素朴な疑問やレジリエンス(resilience)について徹底的に検証してみます。
今回は、ソースデータベースにAmazon Aurora PostgreSQL、連携先にAmazon Redshiftを使用して検証を行います。Amazon Aurora PostgreSQLとAmazon Redshiftの Zero-ETL 統合環境の構築については、以下のブログを参考にしてください。
また、Amazon DynamoDB のAmazon Redshift の Zero-ETL 統合にて、同様の検証したい場合は以下のブログを参考に環境構築してください。「Zero-ETL統合」の部分に関しては、恐らく、Amazon DynamoDB でも検証結果は大きく変わらないと予想しています。
初期データのレプリケーションとフィルタリング
よくある運用を想定して、既存の基幹システムのDB(Aurora PostgreSQL)に対して、Zero-ETL統合を作成して、テーブルには事前にレコードを格納します。RedshiftにDBを作成して、レプリケーションの検証と連携対象のテーブルのフィルタリングを検証します。
テーブルの準備
初期状態は、Aurora PostgreSQLのpostgresデータベースの配下のpublicスキーマの下に5つのテーブルがあります。統合を作成する際のフィルタ設定でdevicesから始まるテーブルのみを連携するようにフィルタリングします。
- devices1: 0レコード
- devices2: 1レコード
- devices3: 10レコード
- test1: 0レコード
- test2: 1レコード
なお、テーブル定義は全て同じです。
postgres=> CREATE TABLE devices1(
postgres(> id varchar(16),
postgres(> data_ts varchar(32) PRIMARY KEY
postgres(> );
CREATE TABLE
postgres=>
postgres=> CREATE TABLE devices2 (
postgres(> id varchar(16),
postgres(> data_ts varchar(32) PRIMARY KEY
postgres(> );
CREATE TABLE
postgres=>
postgres=> CREATE TABLE devices3 (
postgres(> id varchar(16),
postgres(> data_ts varchar(32) PRIMARY KEY
postgres(> );
CREATE TABLE
postgres=>
postgres=> CREATE TABLE test1 (
postgres(> id varchar(16),
postgres(> data_ts varchar(32) PRIMARY KEY
postgres(> );
CREATE TABLE
postgres=>
postgres=> CREATE TABLE test2 (
postgres(> id varchar(16),
postgres(> data_ts varchar(32) PRIMARY KEY
postgres(> );
CREATE TABLE
postgres=>
postgres=> INSERT INTO devices2 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
postgres=> INSERT INTO devices3 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
postgres=> INSERT INTO devices3 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
postgres=> INSERT INTO devices3 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
postgres=> INSERT INTO devices3 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
postgres=> INSERT INTO devices3 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
postgres=> INSERT INTO devices3 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
postgres=> INSERT INTO devices3 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
postgres=> INSERT INTO devices3 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
postgres=> INSERT INTO devices3 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
postgres=> INSERT INTO devices3 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
postgres=> INSERT INTO test2 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
postgres=> SELECT * FROM devices1;
id | data_ts
----+---------
(0 rows)
postgres=> SELECT * FROM devices2;
id | data_ts
--------+------------------------------
CM1001 | 2024-10-30 10:29:06.10416+00
(1 row)
postgres=> SELECT * FROM devices3;
id | data_ts
--------+-------------------------------
CM1001 | 2024-10-30 10:29:06.117095+00
CM1001 | 2024-10-30 10:29:06.122249+00
CM1001 | 2024-10-30 10:29:06.126976+00
CM1001 | 2024-10-30 10:29:06.132434+00
CM1001 | 2024-10-30 10:29:06.136762+00
CM1001 | 2024-10-30 10:29:06.141047+00
CM1001 | 2024-10-30 10:29:06.145428+00
CM1001 | 2024-10-30 10:29:06.149844+00
CM1001 | 2024-10-30 10:29:06.15441+00
CM1001 | 2024-10-30 10:29:06.159134+00
(10 rows)
postgres=> SELECT * FROM test1;
id | data_ts
----+---------
(0 rows)
postgres=> SELECT * FROM test2;
id | data_ts
--------+-------------------------------
CM1001 | 2024-10-30 10:29:06.163668+00
(1 row)
postgres=> \d
List of relations
Schema | Name | Type | Owner
--------+----------+-------+----------
public | devices1 | table | postgres
public | devices2 | table | postgres
public | devices3 | table | postgres
public | test1 | table | postgres
public | test2 | table | postgres
(5 rows)
postgres=>
Zero-ETL統合の設定
以下の設定でZero-ETL統合を作成して、Redshift上にデータベースを作成します。設定手順の詳細は、こちらのブログをご覧ください。
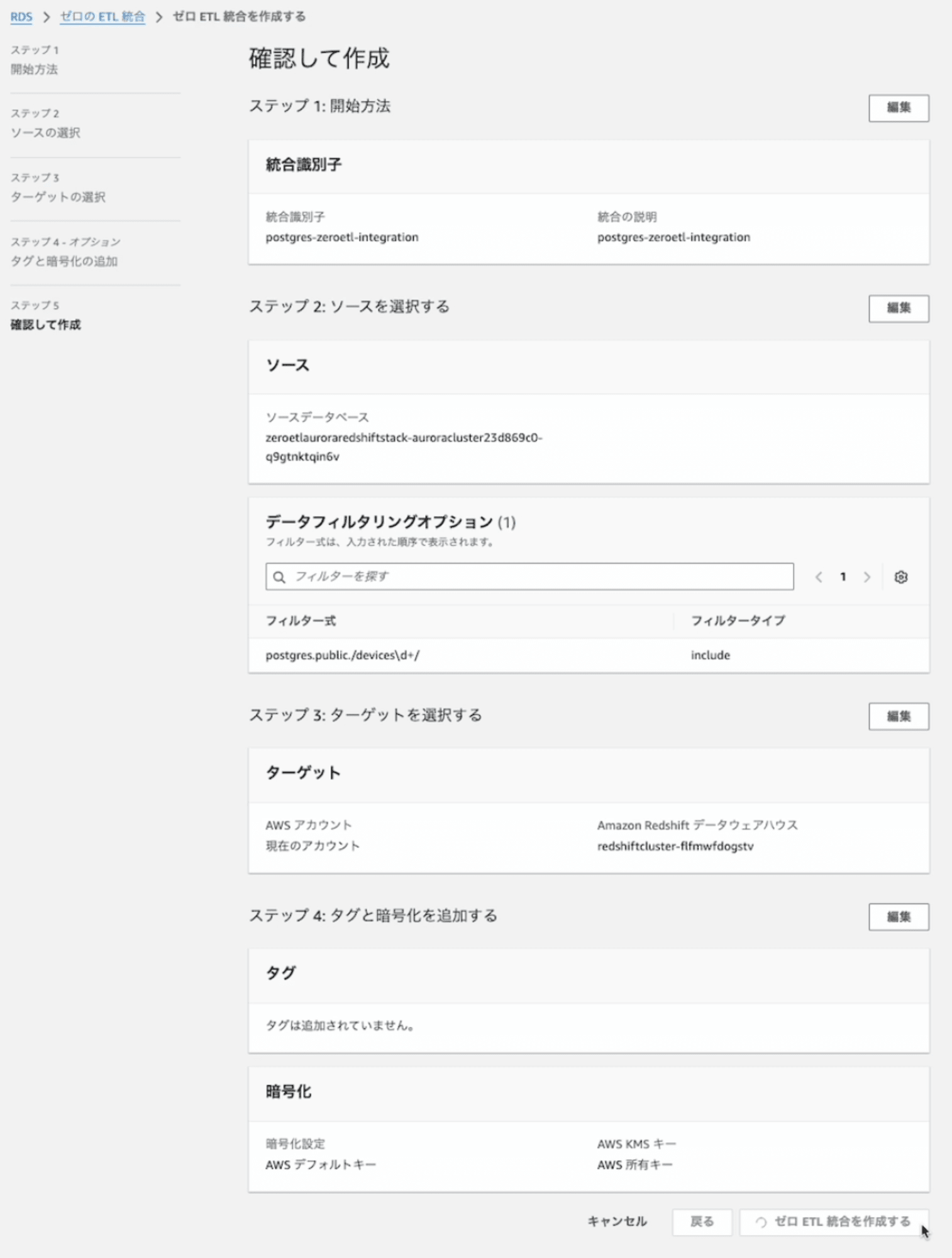
結果: フィルタリングの検証
devicesから始まるテーブルのみが連携されていることが確認できました。
postgres_zeroetl=# \d
List of relations
Schema | Name | Type | Owner
--------+----------+-------+-------
public | devices1 | table | root
public | devices2 | table | root
public | devices3 | table | root
(3 rows)
なお、フィルタリングは、Maxwellフィルタ構文を使用します。
結果: レプリケーションの検証
Zero−ETL統合した時点のデータの状態でレプリケーションされています。
postgres_zeroetl=# SELECT * FROM devices1;
id | data_ts
----+---------
(0 rows)
postgres_zeroetl=# SELECT * FROM devices2;
id | data_ts
--------+------------------------------
CM1001 | 2024-10-30 10:29:06.10416+00
(1 row)
postgres_zeroetl=# SELECT * FROM devices3;
id | data_ts
--------+-------------------------------
CM1001 | 2024-10-30 10:29:06.126976+00
CM1001 | 2024-10-30 10:29:06.141047+00
CM1001 | 2024-10-30 10:29:06.15441+00
CM1001 | 2024-10-30 10:29:06.159134+00
CM1001 | 2024-10-30 10:29:06.117095+00
CM1001 | 2024-10-30 10:29:06.122249+00
CM1001 | 2024-10-30 10:29:06.132434+00
CM1001 | 2024-10-30 10:29:06.136762+00
CM1001 | 2024-10-30 10:29:06.145428+00
CM1001 | 2024-10-30 10:29:06.149844+00
(10 rows)
様々なDDL、DMLの動作を確認
ソーステーブルの新規追加(CREATE TABLE)
Aurora PostgreSQLにdevices4テーブルを追加すると、
postgres=> CREATE TABLE devices4 (
postgres(> id varchar(16),
postgres(> data_ts varchar(32) PRIMARY KEY
postgres(> );
CREATE TABLE
Redshiftにdevices4テーブルが追加され、0レコードであることが確認できました。
postgres_zeroetl=# \d
List of relations
Schema | Name | Type | Owner
--------+----------+-------+-------
public | devices1 | table | root
public | devices2 | table | root
public | devices3 | table | root
public | devices4 | table | root
(4 rows)
postgres_zeroetl=# SELECT * FROM devices4;
id | data_ts
----+---------
(0 rows)
ソーステーブルの1レコード追加(INSERT)
Aurora PostgreSQLのdevices4テーブルに1レコード追加(INSERT)すると、
postgres=> INSERT INTO devices4 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
Redshiftのdevices4テーブルに1レコード追加されることが確認できました。
postgres_zeroetl=# SELECT * FROM devices4;
id | data_ts
--------+-------------------------------
CM1001 | 2024-10-30 11:00:46.687384+00
(1 row)
ソーステーブルのカラムの追加(ADD COLUMN)
Aurora PostgreSQLのdevices4テーブルにnameカラム追加(ADD COLUMN)すると、
postgres=> ALTER TABLE devices4 ADD COLUMN name VARCHAR(255);
ALTER TABLE
Redshiftにnameカラムが追加されていることが確認できます。但し、VARCHAR(255)がVARCHAR(306)になっています。
postgres_zeroetl=# show table devices4;
Show Table DDL statement
----------------------------------------------------------------------------------------------
CREATE TABLE public.devices4 ( +
id character varying(19) ENCODE lzo, +
data_ts character varying(38) NOT NULL DEFAULT ''::character varying ENCODE raw distkey,+
name character varying(306) ENCODE lzo, +
padb_internal_txn_seq_col bigint ENCODE runlength, +
padb_internal_txn_id_col bigint ENCODE runlength, +
PRIMARY KEY (data_ts) +
) +
DISTSTYLE KEY +
SORTKEY ( data_ts );
(1 row)
ソーステーブルのカラムの削除(DROP COLUMN)
Aurora PostgreSQLのdevices4テーブルからnameカラム削除(DROP COLUMN)すると、
postgres=> ALTER TABLE devices4 DROP COLUMN name;
ALTER TABLE
Redshiftにnameカラムが削除されていることが確認できます。
postgres_zeroetl=# show table devices4;
Show Table DDL statement
----------------------------------------------------------------------------------------------
CREATE TABLE public.devices4 ( +
id character varying(19) ENCODE lzo, +
data_ts character varying(38) NOT NULL DEFAULT ''::character varying ENCODE raw distkey,+
padb_internal_txn_seq_col bigint ENCODE runlength, +
padb_internal_txn_id_col bigint ENCODE runlength, +
PRIMARY KEY (data_ts) +
) +
DISTSTYLE KEY +
SORTKEY ( data_ts );
(1 row)
ソーステーブルの1レコード削除(DELETE)
Aurora PostgreSQLのdevices4テーブルに1レコード削除(INSERT)すると、
postgres=> DELETE FROM devices4 WHERE data_ts = '2024-10-30 11:00:46.687384+00';
DELETE 1
Redshiftのdevices4テーブルに1レコード削除されることが確認できました。
postgres_zeroetl=# SELECT * FROM devices4;
id | data_ts
----+---------
(0 rows)
ソーステーブルの3レコード追加(INSERT)、全て削除(DELETE)
Aurora PostgreSQLのdevices4テーブルに3レコード追加(INSERT)した後、全て削除(DELETE)すると、
postgres=> INSERT INTO devices4 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
postgres=> INSERT INTO devices4 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
postgres=> INSERT INTO devices4 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
:
(Redshiftに上記3レコードがリプリケーションされたのを確認した後)
:
postgres=> DELETE FROM devices4;
DELETE 3
Redshiftのdevices4テーブルに全てのレコード削除されることが確認できました。
postgres_zeroetl=# SELECT * FROM devices4;
id | data_ts
----+---------
(0 rows)
ソーステーブルの3レコード追加(INSERT)、全て削除(TRUNCATE)
Aurora PostgreSQLのdevices4テーブルに3レコード追加(INSERT)した後、全て削除(TRUNCATE)すると、
postgres=> INSERT INTO devices4 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
postgres=> INSERT INTO devices4 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
postgres=> INSERT INTO devices4 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
:
(Redshiftに上記3レコードがリプリケーションされたのを確認した後)
:
postgres=> TRUNCATE TABLE devices4;
TRUNCATE TABLE
Redshiftにdevices4テーブルに全てのレコード削除されることが確認できました。
postgres_zeroetl=# SELECT * FROM devices4;
id | data_ts
----+---------
(0 rows)
ソーステーブルの削除(DROP TABLE)
最初にAurora PostgreSQLのdevices4テーブルを削除(DROP TABLE)すると、
postgres=> DROP TABLE devices4;
DROP TABLE
Redshiftにdevices4テーブルが削除されることが確認できました。
postgres_zeroetl=# SELECT * FROM devices4;
ERROR: relation "devices4" does not exist
postgres_zeroetl=# \d
List of relations
Schema | Name | Type | Owner
--------+----------+-------+-------
public | devices1 | table | root
public | devices2 | table | root
public | devices3 | table | root
(3 rows)
Redshift上のZero-ETL統合のテーブルにレコード追加
Zero-ETL統合のテーブルへの更新はできません。
postgres_zeroetl=# INSERT INTO devices3 (id , data_ts) VALUES('CM1001', now());
ERROR: Zero-ETL table cannot be inserted into
Redshift上のZero-ETL統合のテーブル削除
Zero-ETL統合のテーブルの削除はできません。
postgres_zeroetl=# DROP TABLE devices3;
ERROR: Zero-ETL table cannot be dropped
Redshift上のZero-ETL統合のスキーマ削除
Zero-ETL統合のスキーマの削除はできま、、、できてるよーー!!!、何もいいことがないので、やらないでください。
postgres_zeroetl=# DROP SCHEMA public CASCADE;
NOTICE: drop cascades to table devices3
DROP SCHEMA
Zero-ETL統合のテーブルのrefresh intervalの変更
変更手順はこちらのブログをご覧ください。
設定値を変更するには、以下のSQL文を実行します。このクエリは、指定されたデータベースに対して更新間隔を600秒に設定します。
ALTER DATABASE sample_integration_db INTEGRATION SET REFRESH_INTERVAL 600;
refresh intervalは、連携されるデータソースによって、デフォルト値や設定できる範囲が異なります。
Aurora MySQL、Aurora PostgreSQL、RDS for MySQL
- デフォルト値: 0秒
- 設定範囲: 0〜432000秒(0秒〜5日)
Amazon DynamoDB
- デフォルト値: 900秒(15分)
- 設定範囲: 900〜432000秒(15分〜5日)
Zero-ETL統合のテーブルのソートキーの変更
変更手順はこちらのブログをご覧ください。
ソートキーを変更するには、以下のSQL文を実行します。このクエリは、ソートキーをAUTOに設定します。
ALTER TABLE sample_table ALTER SORTKEY AUTO;
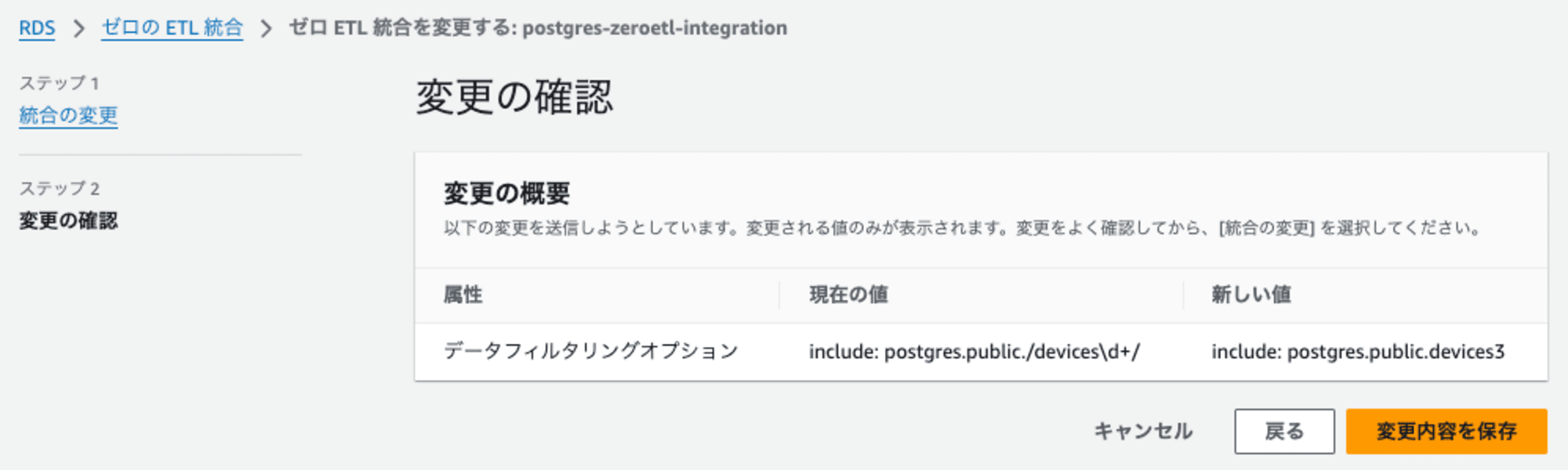
連携対象のテーブルのフィルタリング変更
現在は、devicesから始めるテーブルの全てを対象に設定しています。この設定をdevices3のみ対象とするように設定を変更します。
- 変更前:
postgres.public./devices\d+/ - 変更後:
postgres.public.devices3
下記のように設定変更します。
変更が開始すると、**ステータスが「変更中」**になります。画面上部のメッセージに「**統合の変更に最大30分かかる場合があります」とあります。**データサイズが大きいときは注意が必要ですね。
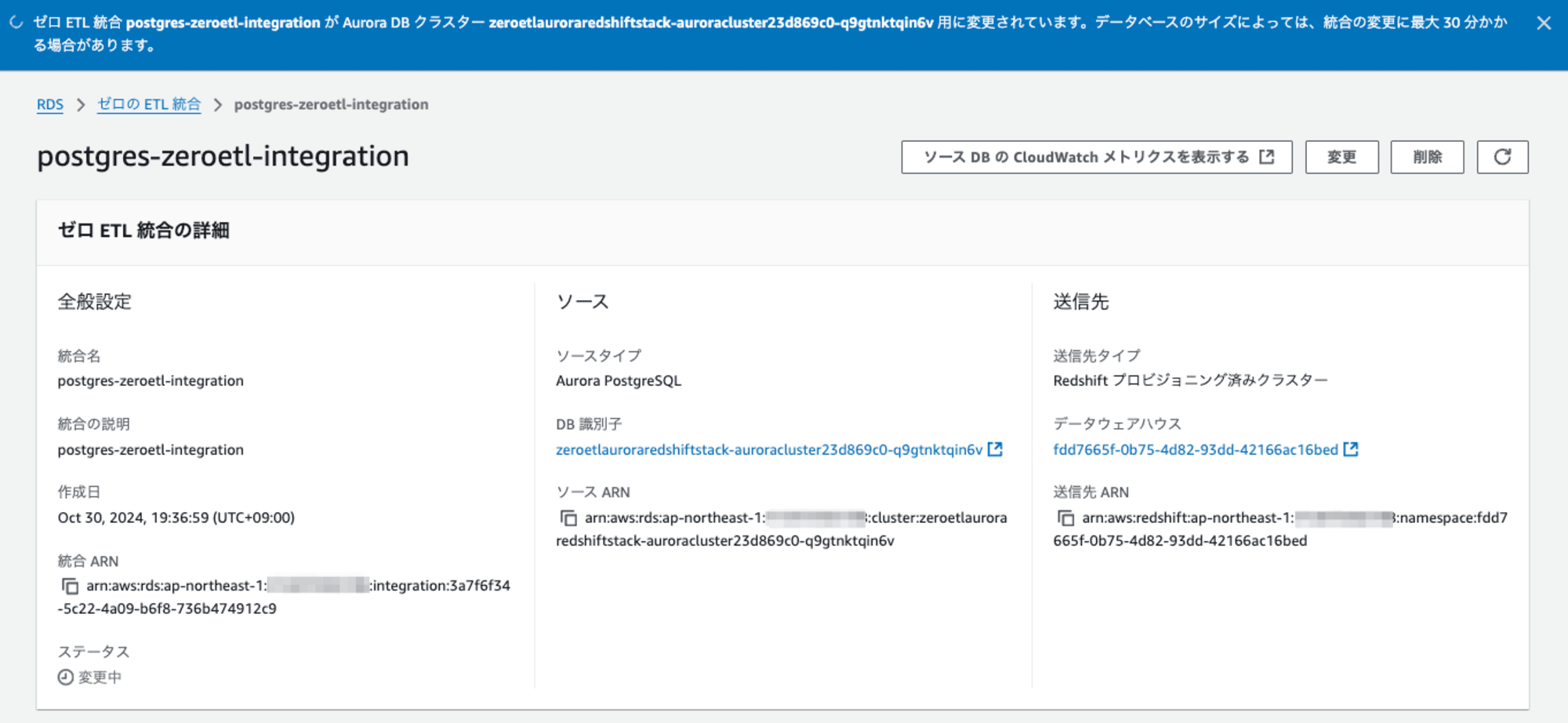
Redshift全体には影響がありませんでしたが、変更中に対象から外されるZero-ETL統合のテーブルを参照すると以下のようなエラーになります。
postgres_zeroetl=# SELECT * FROM devices1;
ERROR: The table "devices1" is not available for querying right now. Make sure the state of your table is synced. See SVV_INTEGRATION_TABLE_STATE for more information.
結果として、ほとんどデータがない状態でしたが、設定が反映するのに11分程度かかりました。設定が反映されるとdevices3テーブルのみが参照できます。
postgres_zeroetl=# \d
List of relations
Schema | Name | Type | Owner
--------+----------+-------+-------
public | devices3 | table | root
(1 row)
Redshiftクラスタの一時停止、再開
レジリエンス(resilience)の検証として、Redshiftクラスタを一時停止(状態が「Paused」)の状態で、Aurora PostgreSQLではレコードを追加します。Redshiftクラスタを正常に起動したときに止まっていた間のデータがロストすることなくレプリケーションできるか確認します。
Aurora PostgreSQLのソーステーブルに5レコード追加(INSERT)しました。
postgres=> INSERT INTO devices3 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
postgres=> INSERT INTO devices3 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
postgres=> INSERT INTO devices3 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
postgres=> INSERT INTO devices3 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
postgres=> INSERT INTO devices3 (id , data_ts) VALUES('CM1001', now());
INSERT 0 1
Redshiftクラスタを正常に起動した後、確認すると止まっていたあいだの更新も反映されています。
postgres_zeroetl=# SELECT * FROM devices3;
id | data_ts
--------+-------------------------------
CM1001 | 2024-10-30 10:29:06.117095+00
CM1001 | 2024-10-30 10:29:06.122249+00
CM1001 | 2024-10-30 10:29:06.132434+00
CM1001 | 2024-10-30 10:29:06.136762+00
CM1001 | 2024-10-30 10:29:06.145428+00
CM1001 | 2024-10-30 10:29:06.149844+00
CM1001 | 2024-10-30 12:11:08.980627+00
CM1001 | 2024-10-30 12:11:09.904512+00
CM1001 | 2024-10-30 10:29:06.126976+00
CM1001 | 2024-10-30 10:29:06.141047+00
CM1001 | 2024-10-30 10:29:06.15441+00
CM1001 | 2024-10-30 10:29:06.159134+00
CM1001 | 2024-10-30 12:11:06.866726+00
CM1001 | 2024-10-30 12:11:08.050862+00
CM1001 | 2024-10-30 12:11:10.890887+00
(15 rows)
Aurora PostgreSQLクラスタの一時停止、、再開
レジリエンス(resilience)の検証として、まずはAurora PostgreSQLを一時停止中、Redshiftクラスタの連携されたテーブルが参照できるか確認します。
Redshiftクラスタは、問題なくクエリできることが確認できました。Redshiftのストレージにリプリケーションして実態を持っているのだから当たり前ですね。
postgres_zeroetl=# SELECT * FROM devices3;
id | data_ts
--------+-------------------------------
CM1001 | 2024-10-30 10:29:06.117095+00
CM1001 | 2024-10-30 10:29:06.122249+00
CM1001 | 2024-10-30 10:29:06.132434+00
CM1001 | 2024-10-30 10:29:06.136762+00
CM1001 | 2024-10-30 10:29:06.145428+00
CM1001 | 2024-10-30 10:29:06.149844+00
CM1001 | 2024-10-30 12:11:08.980627+00
CM1001 | 2024-10-30 12:11:09.904512+00
CM1001 | 2024-10-30 10:29:06.126976+00
CM1001 | 2024-10-30 10:29:06.141047+00
CM1001 | 2024-10-30 10:29:06.15441+00
CM1001 | 2024-10-30 10:29:06.159134+00
CM1001 | 2024-10-30 12:11:06.866726+00
CM1001 | 2024-10-30 12:11:08.050862+00
CM1001 | 2024-10-30 12:11:10.890887+00
(15 rows)
次にAurora PostgreSQLが起動した後、ソーステーブルに5レコード追加(INSERT)、Redshiftに再び変更がリプリケーションすることを確認できました。
postgres_zeroetl=# SELECT * FROM devices3;
id | data_ts
--------+-------------------------------
CM1001 | 2024-10-30 10:29:06.117095+00
CM1001 | 2024-10-30 10:29:06.122249+00
CM1001 | 2024-10-30 10:29:06.132434+00
CM1001 | 2024-10-30 10:29:06.136762+00
CM1001 | 2024-10-30 10:29:06.145428+00
CM1001 | 2024-10-30 10:29:06.149844+00
CM1001 | 2024-10-30 12:11:08.980627+00
CM1001 | 2024-10-30 12:11:09.904512+00
CM1001 | 2024-10-30 12:51:33.694854+00
CM1001 | 2024-10-30 12:51:35.548371+00
CM1001 | 2024-10-30 10:29:06.126976+00
CM1001 | 2024-10-30 10:29:06.141047+00
CM1001 | 2024-10-30 10:29:06.15441+00
CM1001 | 2024-10-30 10:29:06.159134+00
CM1001 | 2024-10-30 12:11:06.866726+00
CM1001 | 2024-10-30 12:11:08.050862+00
CM1001 | 2024-10-30 12:11:10.890887+00
CM1001 | 2024-10-30 12:51:36.350924+00
CM1001 | 2024-10-30 12:51:37.068785+00
CM1001 | 2024-10-30 12:51:37.754416+00
(20 rows)
RedshiftクラスタとAurora PostgreSQLクラスタの両方を一時停止、再開
私は毎晩、両方を一時停止、再開していますが問題ありません。
Zero-ETL統合の削除
いきなり、Zero-ETL統合の削除します。
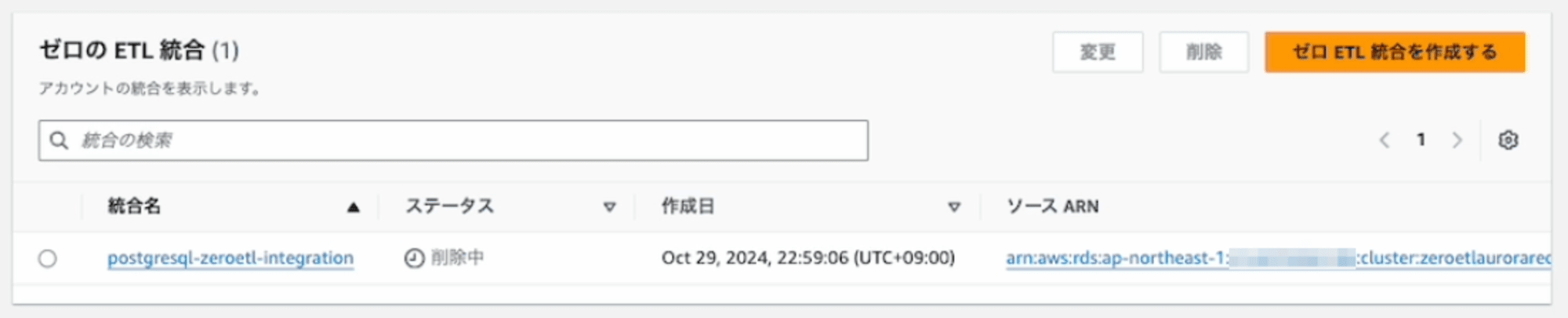
結果は、Redshift上のデータベースは残り、その下のテーブルはSELECTできます。統合されていないため、結果的には削除する必要があります。
最後に
Zero-ETL統合の本番導入や運用設計に向けて、Amazon Aurora PostgreSQLとAmazon Redshiftの Zero-ETL 統合について、様々な観点で検証を行いました。初期データのレプリケーションとフィルタリング、DDLやDMLの動作確認、統合設定の変更、レジリエンスの検証など、幅広いシナリオが網羅したつもりです。
検証結果から、Zero-ETL統合が効果的にデータを同期し、多くの操作に対して期待通りに動作することが示されました。また、クラスタの一時停止や再開時のデータ整合性も確認されており、運用面での信頼性も高いことが証明されました。ただし、Redshift側での直接的なデータ操作には制限があるため、適切な使用方法を理解することが重要です。
なお、今日の検証では顕在化しなかった問題が発生した場合は、以下のトラブルシューティングを参考にしてください。
合わせて読みたい










